
In an increasingly data-oriented world, harnessing data is a top priority for businesses. While having more data is always a good thing, it’s no secret that handling it comes with its challenges. And raw data lacks value without being interpreted, analysed and structured properly.
Data and ETL pipelines have become essential tools to integrate ever-increasing volumes of data and transform it into high-quality information for analysis.
As both data pipelines and ETL pipelines are automatable processes that move data from several sources to a SSOT (such as a data warehouse), they are often misunderstood as one and the same. But they actually move and process data quite differently.
This article breaks down the key differences between data pipelines and ETL pipelines to help you decide which type of process is right for your business.
What is a Data Pipeline?
A data pipeline is an umbrella term to describe a series of processing steps that transfer data from data sources to a destination. Data pipelines automate the process of integrating data, which is critical for running analyses and sustaining operations for businesses.
Components of a Data Pipeline
To understand how a data pipeline can simplify your company’s data management, let’s take a closer look at some of its main components:
- Storage: All components of a data pipeline rely on storage to preserve the data as it moves through the pipeline.
- Pre-processing: big data is “cleaned” by converting unstructured data to structured data and correcting irrelevant, duplicate, and missing data to prepare it for analysis.
- Analysis: Next, the data is analysed to provide useful insights such as identifying relationships between variables in large data sets and comparing new data with existing big data.
- Applications: Data pipelines may use applications during analysis, such as Business Intelligence (BI) and other specialised tools.
- Delivery: The final component of a data pipeline delivers new, analysed, structured data and valuable information to the target repository.
Data Pipeline Characteristics
Data pipelines process data continuously to provide real-time analysis and insights in a matter of seconds. Thereby, they enable real-time reporting, metric updates and predictive analytics to further enhance your business processes.
In today’s data integration market, data pipelines are elastic and agile and can use isolated, independent processing resources. Altogether, data pipelines are easily accessible to everyone in your company and are relatively easy to set up and maintain.
Data Pipeline Types
There are a variety of data pipeline characteristics and features, and here are some examples:
- Batch data pipelines collect data over an interval of time and process it periodically.
- With Cloud native pipelines, data is easily accessible through cloud-based repositories (such as Google BigQuery and Snowflake) and is flexible to handle various data structures.
- Real-time data pipelines use real-time processing (streaming) to move data as soon as it is generated at the source.
- Open source pipelines can be a great low cost alternative to adapt a data pipeline to fit the needs of your business.
Of course, these frameworks are not mutually exclusive and can be combined to build a data pipeline that is tailored to the needs of your company.
What is an ETL Pipeline?
An ETL pipeline is one of the most common subsets of data pipelines and extracts, transforms and loads data into its destination. Businesses often turn to ETL data pipelines to help them with data migration, database replication, marketing data integration or to optimise data for machine learning and AI.
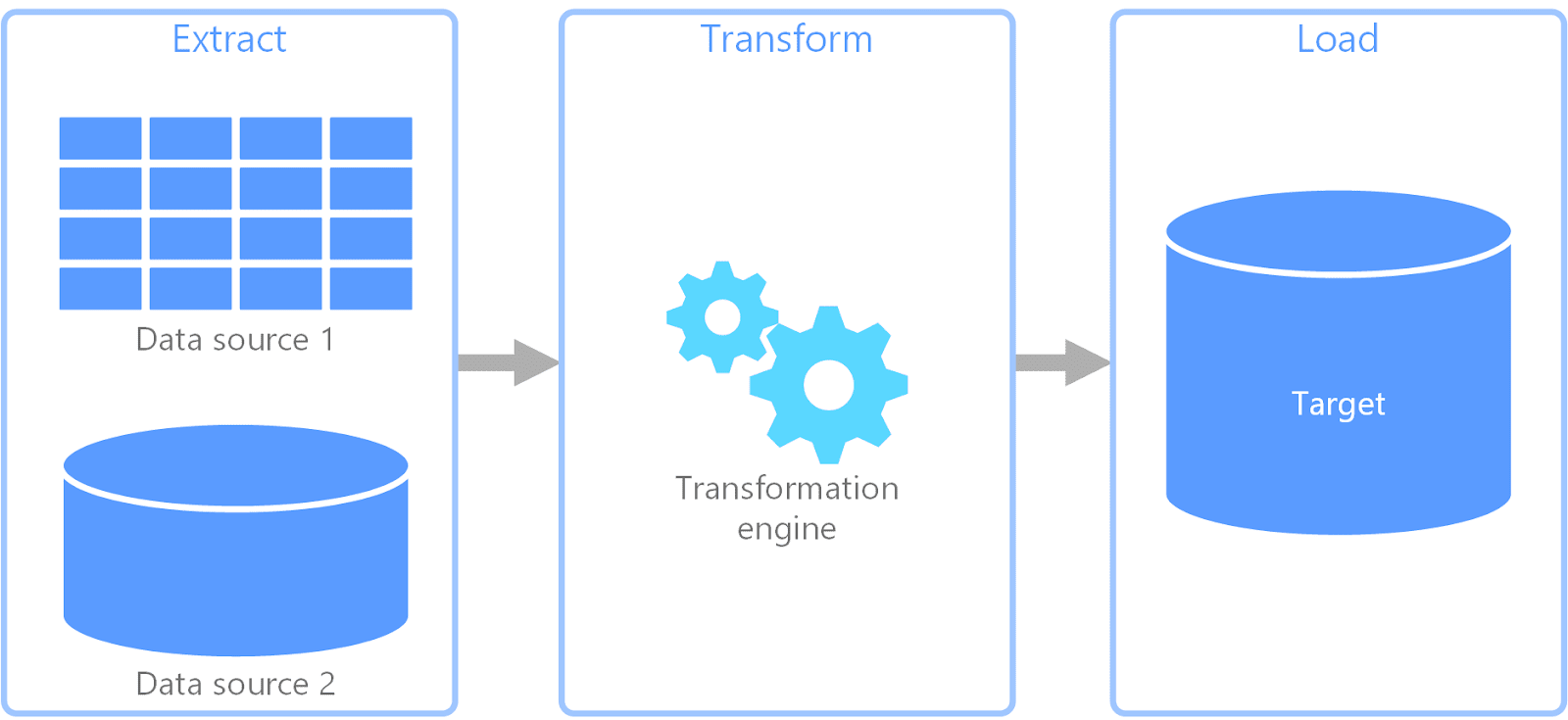
Components of an ETL Pipeline
The components of an ETL pipeline are somewhat similar to those of data pipelines, but let’s look at a full breakdown of an ETL framework and its components for a better understanding:
- Profiling: To prepare for extraction, ETL’s profiling analyses source data to understand the data structure, quality, content and interrelationships.
- Extraction: ETL pipelines extract raw data from the source and store it in a staging area for further processing.
- Transformation: Data is transformed into the desired structure for the destination system. This may include cleansing the data to correct or remove duplicate and inaccurate data; joining, splitting and, sorting data; and organising the data into tables.
- Loading and Monitoring: Loading transformed data from the staging area to the target repository with additional data changes that might be loaded periodically afterwards. Monitoring ensures the ETL data pipeline works correctly, is efficient with growing data loads and remains accurate throughout all stages of the ETL pipeline.
ETL Pipeline Characteristics
Here are some ETL data pipeline characteristics that make them suitable for your company’s data integration:
- ETL real-time data processing tools provide real-time (streaming) processing to extract data and detect any changes in data sources in a matter of seconds.
- ETL cloud based data pipelines will automatically scale source data to accommodate companies’ needs.
- ETL data pipelines use fault tolerant architecture to detect and alert of any malfunctioning, such as node failures or application failures due to untidy data.
- Modern ETL pipeline tools feature checkpointing capabilities that can replay and rewind data to ensure data is processed only once, thus preventing data loss and data duplication.
- Self-service ETL data pipeline tools automate data integration so any employee can easily add data sources to send to the destination.

The Difference Between ETL and ELT
ETL processes are not to be confused with ELT (Extract, Load, Transfer). Both processes extract data in a similar way, but they differ in the way they handle data.
ETLs transform data before loading, whereas an ELT loads it into the data warehouse and transforms it after. ELTs eliminate the need for data staging as they utilise the data warehouse functionalities for transforming data.
With an ELT, your data can be processed and structured as needed—whenever, wherever, fully or partially, and however many times you need to.
In general, ETL pipelines are better equipped for small data sets requiring complex transformations, while ELT pipelines are more suited to large, unstructured data.
3 Key Difference Between Data Pipelines and ETL Pipelines
So, now that we have established the differences in basic characteristics of a data pipeline vs ETL pipeline, what are some of their main differences? Let’s take a look:
- Transforming Data: ETL pipelines always involve data transformation as a key part of the process before loading it into an output destination. Data pipelines, on the other hand, can either transform the data after load (for ex. ELT) or simply transfer data without transforming it.
- Real Time Processing: Automated data pipelines typically perform real-time processing, so your data is constantly updated, giving you real-time analytics and reporting. This differs from ETLs which traditionally move data in batches on a regular schedule.
- End result: An ETL pipeline concludes by loading data into its target repository, whereas a data pipeline doesn’t necessarily end with loading data. In automated data pipelines, loading triggers webhooks in other systems to initiate new flows and processes to support real-time analytics.
Pros and Cons of Data Pipelines vs ETL Pipelines
The differences between data pipelines vs ETL pipelines can present several advantages and disadvantages, depending on your use cases. Here are some aspects you may want to consider:
| Pros | Cons | |
| Data Pipeline | Data pipelines, particularly cloud based natives, reduce costs by reducing the amount of physical storage neededReal-time processing speeds up operations, making the delivery time of valuable information faster, providing real-time analytics and reportingMakes working with big data much easierTriggering other processes after loading data can enable Business Intelligence for gaining valuable insights | Designing a data-pipeline to suit your use cases can become complexTransforming data after loading it can take up valuable timeData pipelines may be effective when they are built but become outdated and inflexible as time goes onThey can be difficult to scale and this can become expensive in the long run |
| ETL Pipeline | Through transformation, ETL enables business intelligence and provides deeper analytics Automated tools aid data migrationETL pipelines can feature checkpointing and fault-tolerant architecture to tackle any malfunctions | Without enhanced tools, ETLs can be inflexible when tackling data debugging Batch processing can slow down data integrationTraditional ETL’s speed limits the amount of data you can transfer and becomes slower when dealing with large loads of dataTraditional ETL pipelines can be difficult to troubleshoot |
Key Takeaways
Despite being used interchangeably, comparing data pipelines vs ETL pipelines presents considerable differences – both with distinct functions to help your company harness the power of data. Let’s recap some of the main points:
- A data pipeline is a set of operations that move data from a source, or multiple sources. Different types of data pipelines include: Batch processing, Cloud Native, Real-time Processing and Open source Data Pipelines.
- ETL pipelines are a subset of data pipelines, and extract, transform and load data to a target repository.
- ETL data pipelines transform data before loading it to destination, whereas ELTs transform data within the data warehouse itself.
- ETL pipelines always involve transformation of data before loading, whereas data pipelines won’t necessarily include transformation. ETL pipelines end with loading, while data pipelines may trigger other processes after loading.
- Data pipelines are great for working with big data but they can be complex to set up and difficult to scale- which can be expensive in the long run. On the other hand, ETL pipelines facilitate deeper analytics as they enable business intelligence but they can be inflexible and difficult to troubleshoot.