
Building a data warehouse is the first step towards effectively managing and leveraging your most precious asset—your data.
As the amount of data we use continues to grow, the need to harness its power has led to the emergence of new tools such as data warehouses.
Without a data warehouse, making sense of data can feel a bit like looking for an uncatalogued book in an entire library. Building a data warehouse can not only provide the “library” for your data to be stored, but also the tools to analyse that data efficiently and reliably.
Keep reading to learn all about the approaches and steps to building a data warehouse.
Why Do You Need A Data Warehouse?

Data warehouses are central repositories of information, but they’re more than simply a dumping ground for your data. Data warehouses store current and historical data in a centralised location so that users can analyse the data comprehensively, easily, and efficiently.
For example, when sales and marketing store their data in separate databases, creating a report based on their combined data requires significant human labour. Building a data warehouse allows those separate databases to be collected into one location where data can be analysed as a whole.
Data warehouses allow teams to focus on their priorities without wasting time scouring decentralised databases for the data they need.
Data Warehouse vs. Data Mart: What Are the Differences?
Data warehouses are data-oriented, whereas data marts are project-oriented. Data marts are also decentralised, whereas a data warehouse is a comprehensive and centralised location that is used across projects.
If a data warehouse is like an ocean of data—vast, diverse, and containing data from all sources—a data mart is like a river—based on a single ecosystem and all flowing in the same direction.
Also, like oceans and rivers, data warehouses and data marts aren’t mutually exclusive; they frequently work together to pull data from the same sources.
Data warehouses store data from all available sources, whereas data marts typically pull their data directly from a data warehouse rather than from the various operational systems.
Because of the difference in focus, data marts are easier to build but don’t have the functionality or flexibility of a data warehouse. On the other hand, data warehouses are more versatile and long-lasting, so building a data warehouse is a more functional option for most agencies.
What Is a Data Warehouse Built of?
There are several components that go into the process of building a data warehouse. Let’s check them out.

1. Storage
Storing data is the backbone of building a data warehouse. Data architects have two options for storing data: physical and cloud-based storage servers. There are several things decision-makers should keep in mind when choosing between storage locations:
- Cost Structure: Setting up a physical server requires a large initial investment both in hardware and labour costs. Additionally, it requires ongoing maintenance and upgrades as the amount of data increases. Cloud-based servers, on the other hand, have a lower initial cost with no hardware investment needed, but represent a larger operational cost.
- Control: Control is both a physical storage server’s biggest pro and its biggest con. Because the storage is entirely within the organisation’s control, that means it’s completely customizable and upgradable. But, it also means that the organisation is responsible for addressing issues as they come up. Cloud-based storage servers are an efficient way of outsourcing expertise to a third party, leaving you with the time and resources to dedicate to your project. But, organisations that use cloud-based servers lose the full control and flexibility of a physical, on-premise server.
- Labour: An in-house, physical server requires ongoing maintenance that involves not only money but also time. One of the biggest advantages of cloud-based servers is that the upkeep is shifted to the storage provider, who takes on the responsibility of maintaining the server.
2. Software
Data warehousing software is the fundamental core of building a data warehouse. Software is what separates a data warehouse from a lifeless repository full of raw data.
The key functions of data warehouse software include processing and managing data so that meaningful insights can be drawn from the raw information. Data warehousing software includes automation, consolidation, collection, organisation, and normalisation tools which allow users to turn terabytes of cold hard data into actionable information.
3. Labour Input
While one of the main functions of data warehouses is to automate tasks and perform analyses that would otherwise be too difficult for human labourers, they still need to be set up and maintained by humans. Some of the roles that may be involved in building a data warehouse are:
- Backend Developers, who are especially involved in creating the warehouse and implementing necessary automation scripts.
- Database Architects who manage the merging of databases into the central repository.
- Data Analysts who are primarily involved in the day-to-day interpretation and analysis of the data.
- Information Systems Managers who oversee the entire project along with any other business intelligence technologies.
Your labour needs will depend on your data needs—some businesses employ multiple data analysts, for example, while others are able to consolidate multiple roles into a few key personnel.
Approaches to Building a Data Warehouse
A good approach to the structure of a data warehouse allows it to operate more efficiently. There are two main approaches to building a data warehouse: Inmon’s approach and Kimball’s approach.
1. Inmon’s Approach
The father of data warehousing, Bill Inmon, developed the model of a normalised data warehouse that’s still widely used today. The aptly titled “Inmon approach” starts by identifying the primary entities of the business—departments, customers, products, etc.—and then creates a detailed logical model of each entity.
Importantly, these logical models are normalised (the process of structuring databases according to specific norms), and the physical data warehouse is built to reflect the normalised structure of the warehouse.
In this approach, data marts are constructed separately for each division of the company (e.g., marketing, sales, etc.). They exist independently of the data warehouse, but they draw data from a communal, centralised database.
The advantage of the Inmon approach is that it preserves the integrity, or the “single point of truth” of the data. Since there’s only one definitive source of data, there is a low opportunity for redundancy or contradiction.
The downside, however, is that this structure requires a high level of investment in the modelling of each entity, and as a business grows, their data warehouse can become exponentially more complicated to maintain.

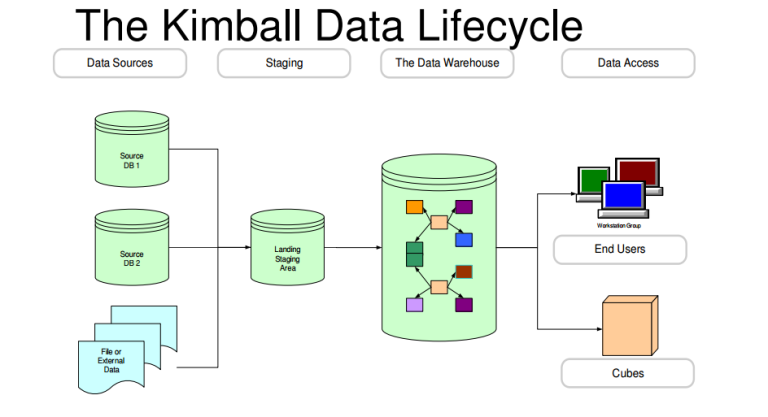
2. Kimball’s Approach
The other side of the coin is Kimball’s approach, named after Ralph Kimball. He proposed a “bottom-up” approach that starts by identifying processes and building the warehouse around the kinds of questions data analysts and decision-makers need to be answered.
In contrast to Inmon’s approach, the data warehouse contains a web of data marts. Data is organised into “star schemas” where data items are used consistently across different data marts.
The strength of Kimball’s approach is that it’s easier to implement, as the time-consuming process of constructing logical models for each entity is avoided altogether. However, unlike the Inmon approach, there is no centralised “true” data repository, so incorrect or redundant data can easily propagate as records are updated.
Data Warehouse Design Approaches
As the Inmon and Kimball approaches illustrate, there’s more than one way to build a data warehouse. Similarly, there are different ways to design a data warehouse.
While the top-down and bottom-up design approaches ultimately work toward the same goal (storing and processing data), there are key differences that Inmon and Kimball recognized that make the approach to designing a data warehouse more nuanced than it may seem.
1. Top-Down Design Approach
Inmon’s approach is an example of top-down design. The top-down design describes a data warehouse where information flows from external sources (business operational systems) through a so-called staging area into data marts.
The staging area is a temporary landing zone for data that’s not ready to be implemented into the model.
From the data warehouse, data can be mined, analysed, and distributed to data marts, where subsections of the data can be used by various entities.
The top-down approach is the most common way for large organisations to build data centres. Since it’s a strong, high-integrity model and data marts can be easily created from the warehouse, it’s a natural fit for organisations with large data needs. However, the expense of upkeep and maintaining an increasingly complex system is prohibitive for some organisations.
2. Bottom-Up Design Approach
Bottom-up design is more reminiscent of Kimball’s approach. Unlike top-down design, where data flows from the data warehouse into data marts, in a bottom-up approach, data flows out from decentralised data marts into the central repository of the data warehouse.
The bottom-up approach includes the same process of data being collected from external sources and flowing through a staging area. But in this case, data is portioned out from the staging area into individual data marts. Then, these data marts form a constellation of data and are consolidated in the data warehouse.
Although both approaches utilise a staging area, it’s technically an optional step. The reason most data warehouses are built with a staging area in mind is that time-sensitive documents should be moved into the database at coordinated times and not simply as soon as the data becomes available.
For example, if the accounting department records all invoices first thing in the morning but receives payments in the afternoon, then a decision-maker who accesses the data in between could be misled into thinking accounts receivable has a higher balance than it really does. And since the main purpose of data is to inform, asynchronous data may then misinform its users.
5 Steps to Building a Data Warehouse
Now, let’s learn what the process of building a data warehouse involves, step by step.

1. Identify Your Organisation’s Needs
What kind of data will you collect? How will it be used? Who will have access to it? Questions like these should be answered before any tangible steps are taken.
Identifying which operational systems will be inputting data, what departments will need data marts, what business processes are being involved, how much data will be stored, etc. is the first essential step to building a data warehouse.
There’s a reason that top-down and bottom-up design approaches are both widely used today—no two businesses are alike, and your unique data needs will dictate what kind of design you should pick.
2. Conceptualize and Roadmap
Once you have a complete grasp on your organisational needs, it’s time to make the first crucial decision: what approach will you take to designing and building your data warehouse?
Whether a top-down or bottom-up approach is appropriate for your business will depend on your organisational needs. Once you’ve fleshed out those needs, it’s time to conceptualise the project.
This is also the stage of the building process where creating a roadmap is important: a schedule for building the data warehouse, a timeline for testing it, key personnel, etc. The second step is all about taking your understanding of your organisation and turning it into tangible, actionable plans.
3. Analyze Data Sources
Once you have a plan in place, it’s time to start taking action. Whether you use Inmon’s or Kimball’s approach, analysing your data sources is a key step.
The third step involves analysing the sources of your data and identifying how it needs to be transformed and organised so that it’s usable for decision-makers.
What file formats is data collected in? How often does new data become available? How do pieces of data relate to each other? These details are all important to note, and they can help you determine if some of your data needs to be normalised.
4. Development
Now that the prerequisite identification, planning, and analysis have taken place, development is the next substantial section of your building process. Because this step involves developing, testing, and implementing every detail of your data warehouse, the development stage may take several months.
Security is one major component of the development stage. Data is your most precious asset, and data breaches are costly, time-consuming, and harmful. The average data breach costs over $4 million, so it’s worthwhile to take your time implementing rigorous security measures during the development phase.
Development also includes performance tweaking. Data warehouses are complex systems, and the efficiency of your warehouse is a premium asset. Time spent improving the performance of your data warehouse will pay dividends in labour hours saved down the road.
5. Implementation
Once your data warehouse has been built, it’s time to implement it in your agency. The process of implementing a data warehouse includes several steps, such as migrating data, implementing automation processes, and training users on how to use it.
One of the key strategies of implementation is to launch discrete data marts in usable chunks, so that users of the data can start using it right away. For example, if a department accesses one type of data from a data silo and another type from a data warehouse, it will lead to confusion, redundancy, and inefficiency. Each data mart should be implemented in its entirety as data is gradually migrated.
Then, it’s time to set up the automation processes for any redundant, click-intensive tasks. You can implement other custom automations that will simplify your business processes, too.
Finally, in order for your data warehouse to be implemented effectively, it’s important to train users on how to navigate and use the new system. Training large groups of users is difficult for any industry, but once they see what the data can do, most users will be as excited about the change as you are.
How Much Does It Cost to Build a Data Warehouse?
Asking “how much does it cost to build a data warehouse?” is almost like asking “how much does it cost to buy food?” It depends on whether you’re buying a burger or catering an entire wedding—the price of building a data warehouse varies drastically based on the scale and features of your data warehouse.
Data warehousing costs can easily vary between 5 and 6-digit prices depending on the size of your business and the amount of data you have.
Enterprises can even anticipate costs into the millions, as an enterprise data warehouse is very complex to build and maintain.
Data Warehousing Use Cases
Data warehousing benefits can be enjoyed by various businesses that aim overcome different challenges. Here are some of the most common use cases for a data warehouse.

1. Data-Mining Analytics
The ability to analyse large sets of data is one of the biggest reasons to consider building a data warehouse. A data warehouse allows you to do the kind of advanced data mining and analytics that would be impossible to do manually.
Data-mining is the process of looking for connections and patterns in large data sets, a task that challenges even the most adept humans. Technology is much more efficient than human labourers at recognizing high-level patterns in data. But in order for those patterns to be meaningful, an entire pool of relevant data has to be accessible to the system.
That is why data warehouses are a particularly useful tool for analysis, allowing for a company’s entire repository of data to be mined for insights.
2. Sales Campaigns
Building a data warehouse takes the ambiguity out of sales and marketing campaigns.
Customer Relationship Management (CRM) software has taught us that staying on top of potential leads doesn’t have to be as harrowing and tedious as it used to be.
Data warehousing makes it harder for leads to slip through the cracks, and big data analytics gives you insight into your potential customers that goes beyond the surface-level understanding of a rolodex or email newsletter.
Data warehouses also allow teams to coordinate from a centralised data source, so that sales campaigns can roll out synchronously and rapidly.
3. Quality Control
Data warehouses are a powerful tool not only for analysing data but also for inspecting the quality of the data itself.
As any bratwurst enthusiast will tell you, the final product is only as good as what goes into it. Bad data results in bad analytics, and bad analytics results in poor decision-making.
Analysis tools can give decision-makers insights into the integrity of their data that manual labour can’t replicate, but the process of quality assurance is costly and labour-intensive.
Building a data warehouse can give you high-level insights into what kind of data is flowing into your system, how it’s being normalised, and how complete it is, with no additional expenses for quality assurance.
4. Migrating Legacy Systems
Technology is truly amazing, but it isn’t easy to charge a modern cell phone with a charger from the last decade, for example. Retrofitting legacy systems to work with modern-day analytics tools is a herculean task—or at least, it would be a herculean task without a data warehouse.
Building a data warehouse enables you to transform data from legacy systems into normalised formats that current platforms can utilise. Once again, data warehouses can automatically perform tasks that would not be worth the time it would take a human to do them manually.
Let Acuto Build a Data Warehouse for You
The complexity of data warehousing can be both exciting and intimidating, but the good news is that data warehousing doesn’t have to be difficult and expensive!
Acuto specialises in building data warehouses that are customised to your unique needs. While other data warehousing solutions can either be inflexible and/or unaffordable, Acuto provides the best of both worlds: custom data warehouses at more affordable prices.
Acuto can also build automation scripts that simplify data reporting and allow different data sources to interact with each other.
There are many things to consider when it comes to data warehousing, but the most important thing is that you harness your greatest asset to accomplish the greatest good for your organisation. And you can easily do that with the help of Acuto!
Key Takeaways
That concludes our comprehensive guide to building a data warehouse! Let’s go over the main points:
- A data warehouse consists of storage, software, and labour input.
- Inmon’s top-down approach starts by identifying entities and building a data warehouse around normalised logical models.
- Kimball’s bottom-up approach starts by identifying processes and building star schemas around constellations of data marts.
- The steps of building a data warehouse are: identifying your business requirements, conceptualising and roadmapping; analysing data sources, developing the data warehouse, and finally implementing it.
- Data warehouses can vary in price depending on your individual needs and agency size.