
It’s no secret that data warehousing has become increasingly popular among agencies. They rely on a single source of truth to make smart, data-driven decisions.
But to get the best out of your data warehouse, you need to choose the right architecture type when building it.
There are three different data warehouse architecture types to choose from. However, each has its own distinct characteristics that are suitable for the purposes of different agencies.
In this article, you’ll learn all about data warehouse architecture types, including layers, components and characteristics. This will help you choose the right one for your agency.
But first, let’s take a look at what data warehousing architecture is.
Data Warehouse Architecture
Data warehouse architecture is a framework that defines the data warehouse design. It enables a proper data communication process, starting from the processing of the data until it gets to the end-user.
It focuses on finding the most efficient method of taking information from raw data and converting it into simple, digestible information that enables valuable business insights.
What’s more, data warehouse architecture helps you understand the different layers and components of a data warehouse by providing an overview of how all the components interact with each other and what their purpose is.
Once you have a well-developed data warehouse architecture in place, you get a clearer picture of the things required to build an enterprise-wide information system that can act as a central repository for various types of data.

3 Types of Data Warehouse Architecture
There are three common data warehouse architecture types typically used for building a data warehouse:
- Single-Tier Architecture
- Two-Tier Architecture
- Three-Tier Architecture
Each type of data warehouse architecture has its own benefits and limitations. Let’s explore the unique characteristics of each one of them.
1. Single-Tier Architecture
The single-tier data warehouse architecture reduces the amount of data stored in a data warehouse by building a more compact data set. Its advantage is that it helps remove data redundancies and improves the quality of your data.
However, it isn’t the ideal solution for agencies that own large volumes of data and operate with multiple data streams because it’s inefficient.
The single-tier architecture has three layers:
- A source layer
- A data warehouse layer
- An analysis layer
In the single-tier architecture, only the source layer is physical. The data warehouse layer is virtual and provides data in a multidimensional view, created by an intermediate processing layer.
One drawback of the single-tier architecture is the lack of separation between analytical and transactional processing. And that’s why this type of data warehouse architecture is not used frequently.
To overcome this challenge, you need…
2. Two-Tier Architecture
Unlike the single-tier architecture, the two-tier architecture contains a data staging area that ensures any data you load into the warehouse is cleansed and in the right format. It’s found between the source layer and the data warehouse layer, as depicted in the image below.
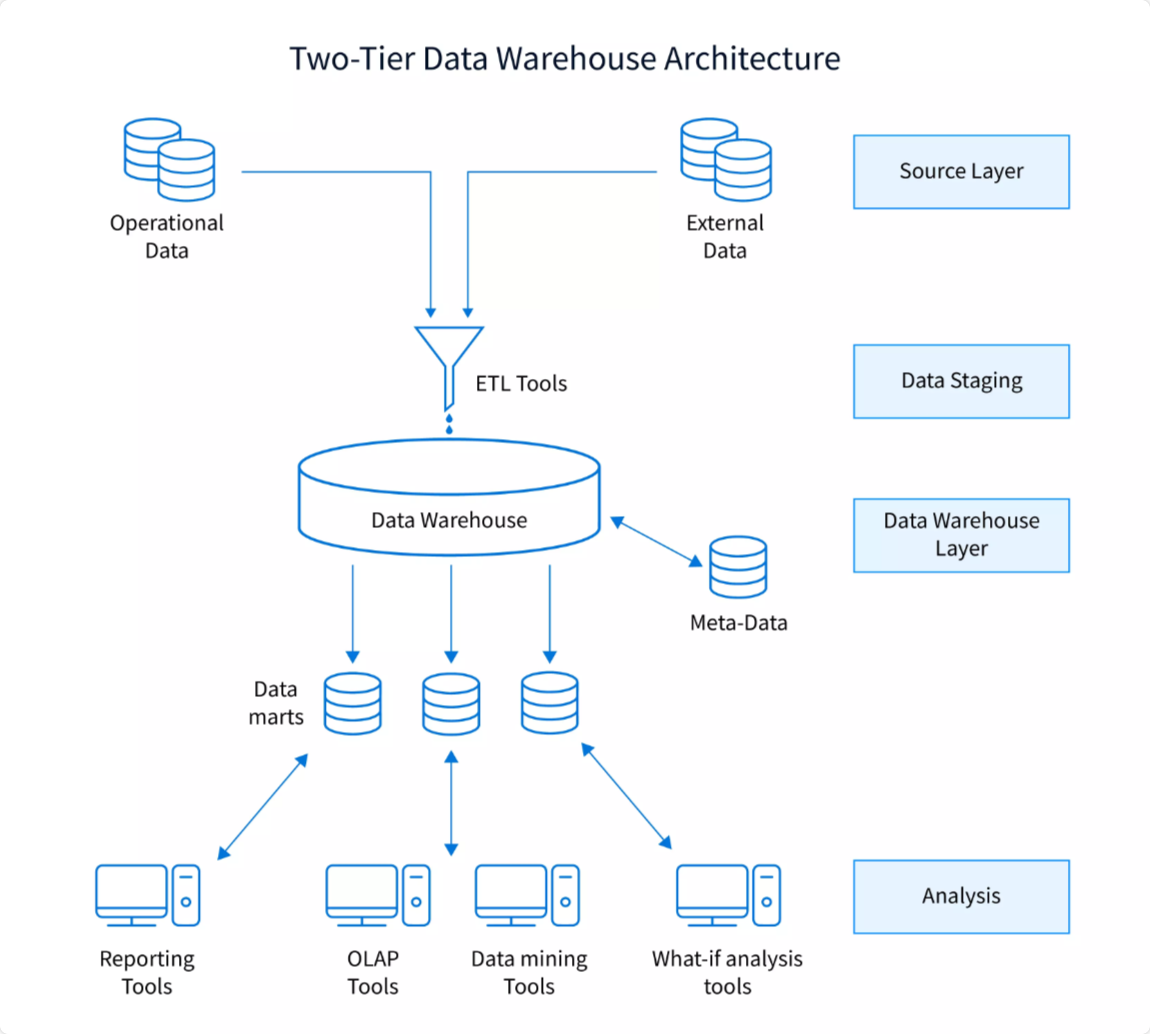
Most businesses that use data marts as a server make use of the two-tier data warehouse architecture, which is also made up of two tiers:
1. The Data Tier
This is the layer where actual data is stored after various ETL processes have been used to load data into the data warehouse.
It’s also made up of three layers:
- A source layer
- A data staging layer
- A data warehouse layer
2. The Client Tier
This layer is where clients can use data stored in the data warehouse to generate insights for making informed, data-driven decisions. You can modify or transform this layer based on the data trends that you discover from your analysis reports.
And it’s made up of a single layer:
- An analysis layer
Some disadvantages of the two-tier architecture are that it’s not scalable, has network limitations, and only supports a small number of users.
3. Three-Tier Architecture
The three-tier architecture is what most organisations go for when building a data warehouse system. It solves the connectivity problems that the two-tier architecture commonly faces.
The three-tier architecture is made up of:
- A source layer
- A reconciled layer
- A data warehouse layer
The three-tier architecture is useful for extensive, enterprise-wide systems. But its disadvantage is the additional storage space it uses through the redundant, reconciled layer.
The three-tier architecture also has three tiers:
- A bottom tier
- A top tier
- A middle tier
These three tiers are commonly called the layers of a data warehouse architecture. Let’s take an in-depth look at these layers.
Layers of a Data Warehouse Architecture
1. Bottom Tier
The bottom-tier, also called the data warehouse layer, is where data is extracted, transformed and loaded into the data repository using backend tools.
2. Middle Tier
The middle tier is responsible for arranging data into a more suitable structure for complex querying and analysis. This process is done with an Online Analytical Processing (OLAP) server and it’s implemented using two models:
- The Relational OLAP model (also called ROLAP), which assigns multidimensional data processes to standard relational operations.
- The Multidimensional OLAP (also called MOLAP) model, which implements multidimensional information and operations.
3. Top Tier
The top-tier is basically the front-end layer that houses various tools and APIs (Application Programming Interfaces) you can use for high-level data analysis, querying, reporting and data mining. It’s where end-users can access, interact and extract data from the warehouse.
5 Main Components of a Data Warehouse Architecture
Every data warehouse is different. However, all of them are characterised by a specific set of components.
Here are the five main components of the data warehouse architecture and their functions.
1. ETL Tools
The data coming from the source layer is in different formats. As such, it needs to be normalised and cleansed before going into the data warehouse.
That’s the job of ETL Tools, an acronym for Extraction, Transformation and Loading tools.
ETL tools extract data from multiple sources, transform it into a suitable format, and load it into the data warehouse.
2. Database
This is the central repository of a data warehouse architecture where data from the various data sources is stored and made accessible for analysis and reporting.
When building a data warehouse, you can choose from any of these four database types:
- Relational databases (Microsoft SQL Server, SAP),
- Analytics databases (Teradata, Greenplum),
- Cloud-based databases (Amazon Redshift, Microsoft Azure SQL), or
- Data warehouse applications (SAP Hana, Oracle Exadata).

3. Metadata
Metadata, in simple words, is “data about data”. Its function is to describe the structure of data in a warehouse and how it’s related to other data in the warehouse.
4. Bus & Data Marts
A data bus determines how data flows in a data warehouse. A data marts, on the other hand, is a subset of a data warehouse used for segmenting information into categories for a specific group of users.
5. Access Tools
Access tools are used to tap into a data warehouse and uncover insights from the data you have. They can be divided in four categories depending on the use for the tools:
Querying & Reporting tools: these are used for querying the database for specific data users need and generating reports based on certain requirements.
OLAP tools: these give users a multidimensional view of the data contained in a data warehouse and analyse complex datasets.
Data mining tools: these automate the process of mining large amounts of data to discover patterns, trends and relevant links between datasets.
Application Development tools: these help users create custom reports for reporting purposes when analytical tools fall short.
Characteristics of a Good Data Warehouse Architecture
Now, let’s take a look at some characteristics of a good data warehouse architecture that allow agencies to get more out of their data warehouse.
- High security: As it’s often claimed, data is the new gold. That’s why it’s crucial to have a highly secure data warehouse that will help you monitor and prevent unauthorised users from accessing your data.
- Simple Administration: The data warehouse management structure should be as simple as possible so it’s easy to maintain the data warehouse.
- Scalability: Every data warehouse architecture should be scalable. In other words, your hardware and software platforms should scale as the needs of your organisation grow. They should be able to meet your analytics requirements without the need for a complete overhaul to save you resources in the long run.
Build a Data Warehouse With the Help of Acuto
If you need help consolidating all your scattered data into a single, unified data warehouse without breaking the bank, Acuto has you covered. We are a marketing tech agency that builds solutions tailored to your agency’s unique strategies – delivered by a team of developers and cloud engineers with a background in PPC.
We can help you set up and manage a BigQuery data warehouse tailored to your business, so you can sit back and focus on doing what you’re great at. Our data warehouse services have helped many agencies from the planning phase through to implementation.
Get in touch if you would like to learn more about our flexible, infinitely scalable and cost-effective data warehousing services.
Key Takeaways
Without a doubt, having solid knowledge of different data warehouse architecture types will help you pick an effective data warehouse system for your agency.
To summarise:
- Data warehouse architecture defines the overall architecture of data communication, from processing the data to presenting it to clients.
- There are three main data warehouse architecture types: single-tier, two-tier and three-tier data warehouses.
- Every data warehouse has the same vital components within its architecture, namely: ETL tools, databases, metadata, bus & data marts and access tools.
- To get the best out of your data warehouse, it should have high security, simple administration and scalability.